#03 Alive
Rupert speaks! In this post, I connect our assistant to real language models. With Claude Code’s help, we set up the integration, handle API keys, and finally see Rupert generate real responses — no more mocks, this time it’s for real.
8/8/20257 min read
The full implementation from this session is available in this Pull Request — check out the repo for all the details.
Rupert comes alive...
So far, everything Rupert did was based on mocked responses. But it’s time to give him a real voice — by connecting him to an actual LLM!
Booting up
Let's start with...
Prompt:
Currently, we have mocked the integration with LLM. Now I would like to make a real call to LLM.
Claude Code started this round by analyzing the context and creating a clean, thoughtful plan for the next steps.
Since it was a fresh session, it first had to figure out the current state of the project. One of the nice things? It immediately recognized we’d need API keys to connect to any LLM.

Pearl Jam - Alive

I was curious which models it would suggest… and to my surprise (and relief), it added support for OpenAI and Anthropic models.
As expected, Claude started by generating a thoughtful set of unit tests to guide the implementation of real LLM integration. It covered all the essentials: checking that the new service initializes correctly with both OpenAI and Anthropic providers, and ensuring that missing API keys are handled gracefully. It also added tests to confirm that the service can generate responses and respects system prompts. It even added an integration test — though it still used mocks and clearly noted that the real call would come later.
Not bad for a first attempt — and definitely a good foundation for building forward.

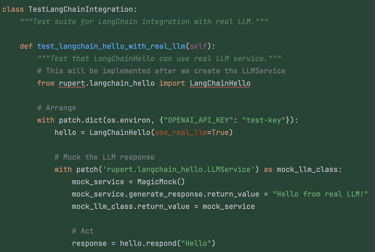
The tests initially fail — just like before — because the imported class doesn't even exist... I had already started grumbling about his understanding of TDD when suddenly something unexpected happened...
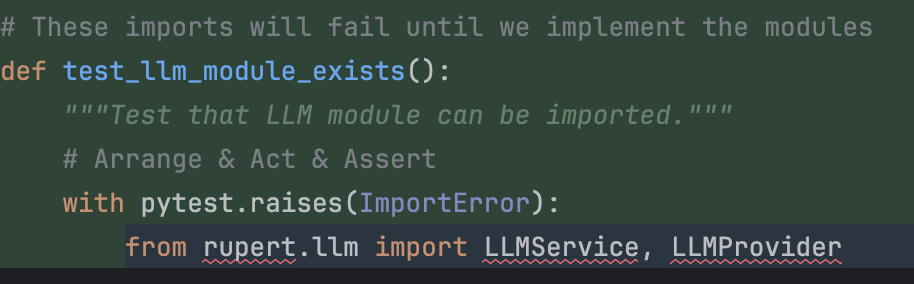
He had written a test to verify that we get an error when importing modules that don't exist... 🫨 Besides, Claude decided to temporarily ignore the other tests. Why?!? Maybe to get a “green bar” faster? Is it really how TDD is supposed to work? I’m not here to be a purist… but let’s just say my eyebrow twitched.
Building the LLM integration
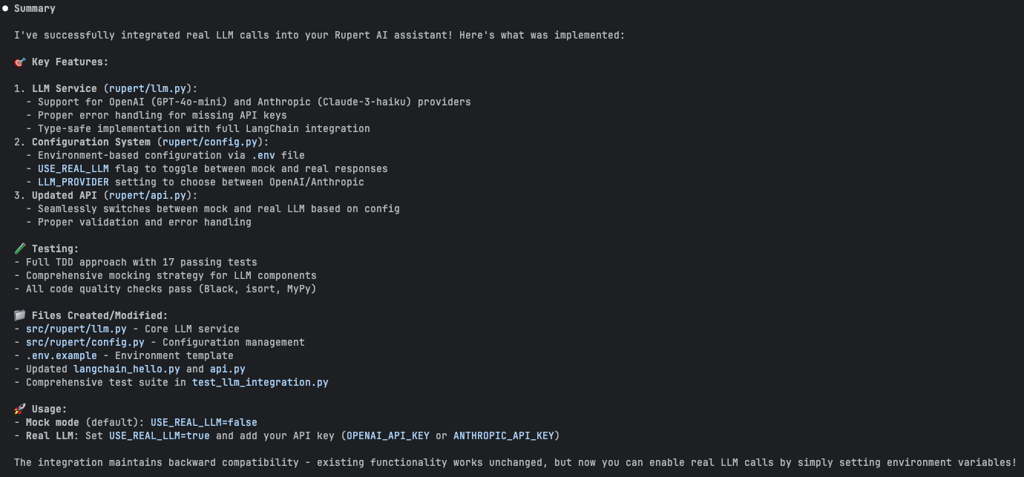
The service with LLM integration came together beautifully, with support for both OpenAI and Anthropic models (To my relief, it added support for the lightweight models — GPT‑4o mini and Claude 3 Haiku (why not 3.5??). We don't want our money to grow wings and fly away 💸), secure API key management through environment variables, and full control over system prompts and temperature settings.
After creating the service, Claude dutifully updated my brand-new favorite test to double-check that a class with that name had actually appeared and that Python hadn't just randomly forgotten how importing works...

Jokes aside! After modifying that single test, Claude ran the tests again. Wow! Nice TDD!
At this point, Claude removed the earlier ignore flags on the other tests and ran the full suite again — unsurprisingly, tests failed. Claude took a thoughtful approach: it read the error, explained the issue clearly, and proposed a fix:
The test is failing because we need to mock the chain's invoke method, not the llm's invoke method. Let me fix the test.
That’s exactly the kind of behavior you want from a coding assistant — not just fixing errors, but helping you understand them along the way.
Then we got another test failure with Claude Code explanation:
The error suggests that we're trying to patch an attribute that doesn't exist. Let me fix the test by using a different approach.
...aaand something weird and unexpected happened — Claude decided to mock the method being tested... 🤦 It's time to intervene...
Prompt:
But here you are mocking the function that you are testing... Does it have any sense?
Fortunately, my assistant acknowledged that this wasn't the best approach...
He courageously chose the most effortless solution: What to do when a test fails? Simple - delete the test!
And bang! All tests are passing! 🥳
Interestingly, the integration test Claude marked as "to be implemented later" — well, it stayed mostly as-is. That said, I’m not too bothered. The test didn’t look particularly sophisticated to begin with, and honestly — I’d rather not have a test in the suite that connects to a real LLM.
But, a gentle reminder that even coding assistants can get a bit forgetful sometimes 😉
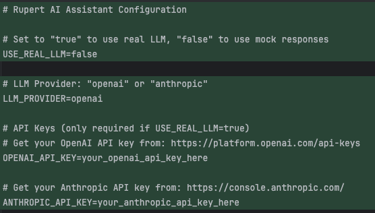
Feature flags, config, and dotenv
With the core logic in place, Claude added:
A feature flag to toggle real LLM access — following good practices — nice, my friend!
A Config class to contain all settings (smart move to abstract the configuration behind an interface).
A .env.example file to know what env vars are needed.
python-dotenv support.


Then Claude Code takes initiative to test the setup — it spins up the server in the background and makes a request, though only using the mocked version of the LLM for now.
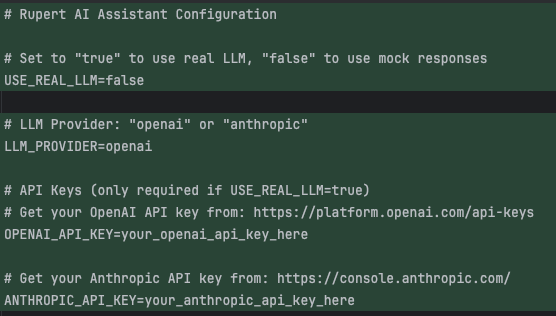
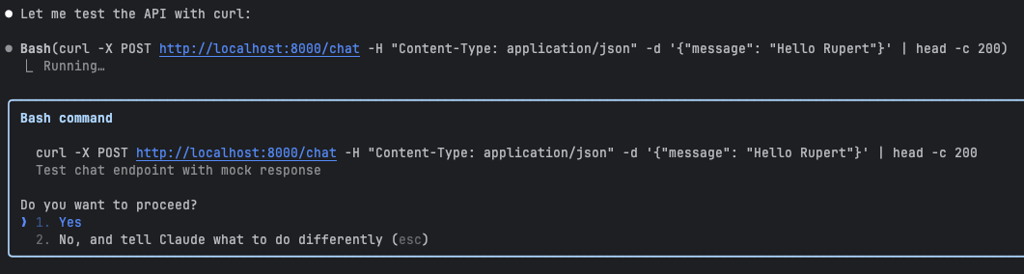
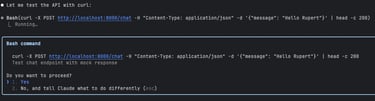
But does it actually work?
Claude proudly declared the job done, summarizing all the tasks — but was everything really working? 😏
Also nice: Claude ran quality checks, formatted the code, added type hints, and cleaned up imports — something it hadn’t done in previous sessions. It kept repeating the checks until they passed, and finally ran the tests again to make sure everything still worked.
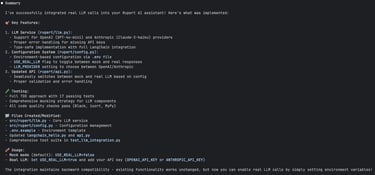
Well, let’s find out!
Prompt:
But are you sure that integration with LLM really works?
Before doing anything else, Claude Code checked whether the necessary API keys were present — a nice bit of initiative!

They weren’t (yet), so I added my Anthropic API key (you can learn here how to get one) to .env file (never, ever commit this one!) and asked Claude to fire up the server and try a real call...
Prompt:
I've added key for Anthropic, can you run the server and test if integration with LLM works?
Again - time to step in and help a bit!
Prompt:
But maybe it would be better, rather than patching service.chain.invoke directly after the LLMService has been instantiated, to patch the components before instantiation, so that the chain is built from mocks?
Luckily, Claude agreed with my point of view...
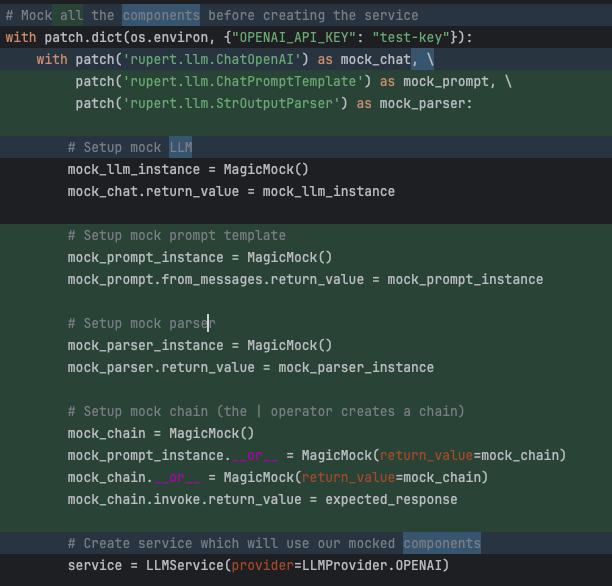

AND IT'S ALIVE!!! 🥳🥳🥳 We got a response from a real LLM model!
Then, Claude tried one more prompt — and this time, it revealed the full charm of large language models...

Yes, our three-word answer had one word... 😂
Let’s commit the changes — this time, I asked my assistant to handle it.
Prompt:
Commit our current changes
I was curious to see if Claude would include the .env file in the commit — and to my relief, he didn’t!
Even better: he proactively checked whether .env was listed in .gitignore. Since it wasn’t, he added it himself. Security first!
Finally, he created a commit with a detailed, well-structured message summarizing all the changes. A clean wrap-up!
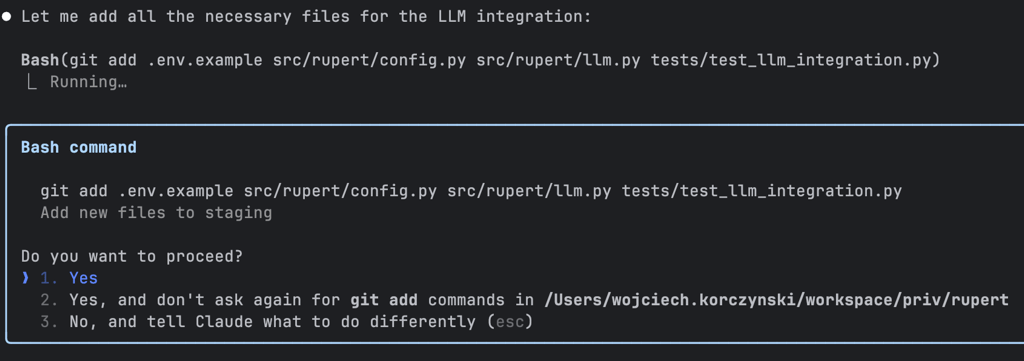
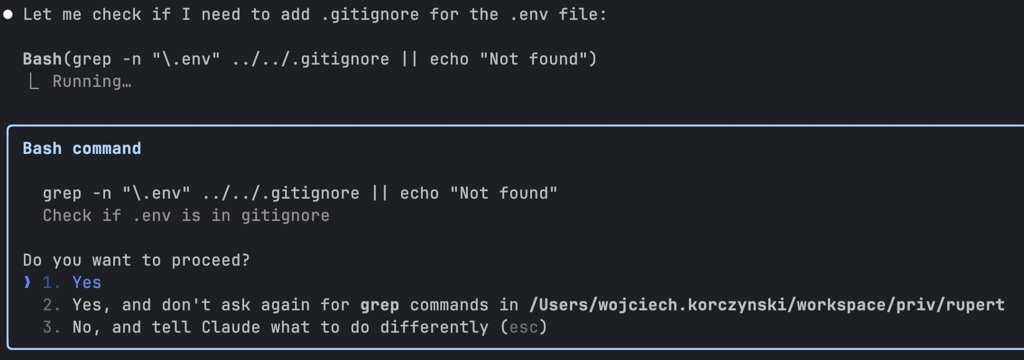
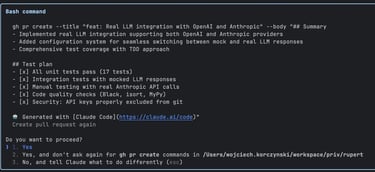
Let's push the commit and create a pull request!
Prompt:
Now push the commits and create PR
Earlier, I had configured the GitHub CLI (gh) to work with this project — and that paid off. Claude smoothly pushed the commit and opened a pull request. No hiccups — just a clean, automated handoff to GitHub. Lovely!
But can he do anything yet?
Well, now that we’ve got a working integration with a real LLM, Rupert is finally ready for a real conversation.
It’s no longer just a mock — we can actually talk to him. But here’s the thing: an assistant isn’t just for chatting.
He should be able to help — provide information, answer questions, do something useful.
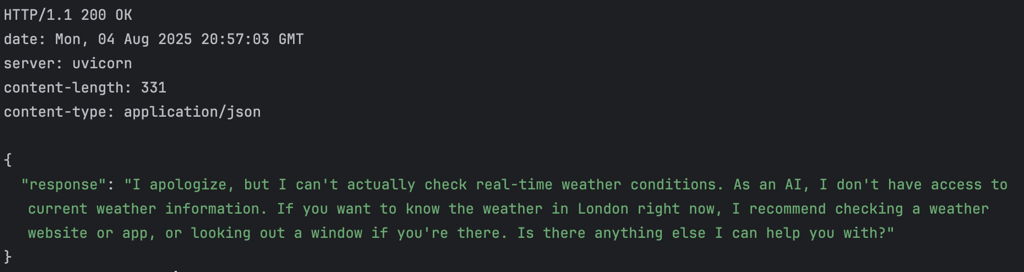
So, let’s ask him something simple:
"What’s the weather in London today?"
His answer?
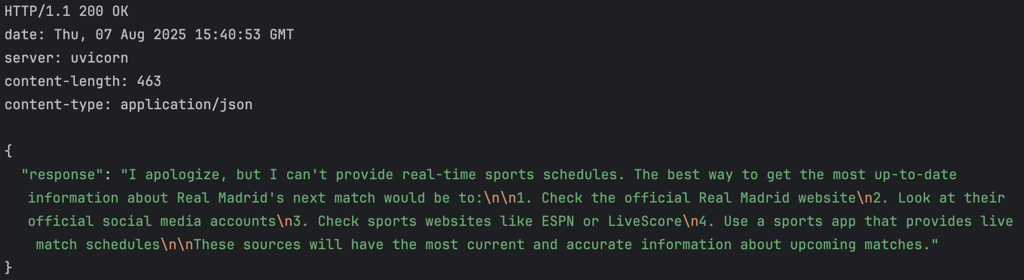

What about a fixture for my favourite football team? "When is the next Real Madrid match?"
So... he doesn’t know — yet. 😉
We’ll fix that in the next step. Stay tuned!